Cluster Overview
Instance table with role badges, ready/WAL status dots, connection bars, disk usage, and timeline IDs. Expand to see per-pod details.
Instance Detail
Drill down to see disk vs WAL breakdown, WAL statistics, per-database sizes with cache hit ratios, table stats, and slow queries.
Profile Editor
6-tab configuration editor: General, Volumes, Resources, PostgreSQL params (50+ parameters), HBA Rules, and Recovery Rules.
Deployment Rules
Map profiles to satellites via label selectors. When a rule matches, clusters are auto-created and pushed. Fleet-scale management.
Switchover Progress
9-step switchover progress modal with real-time WebSocket updates, point-of-no-return indicator, and rollback status for pre-PONR failures.
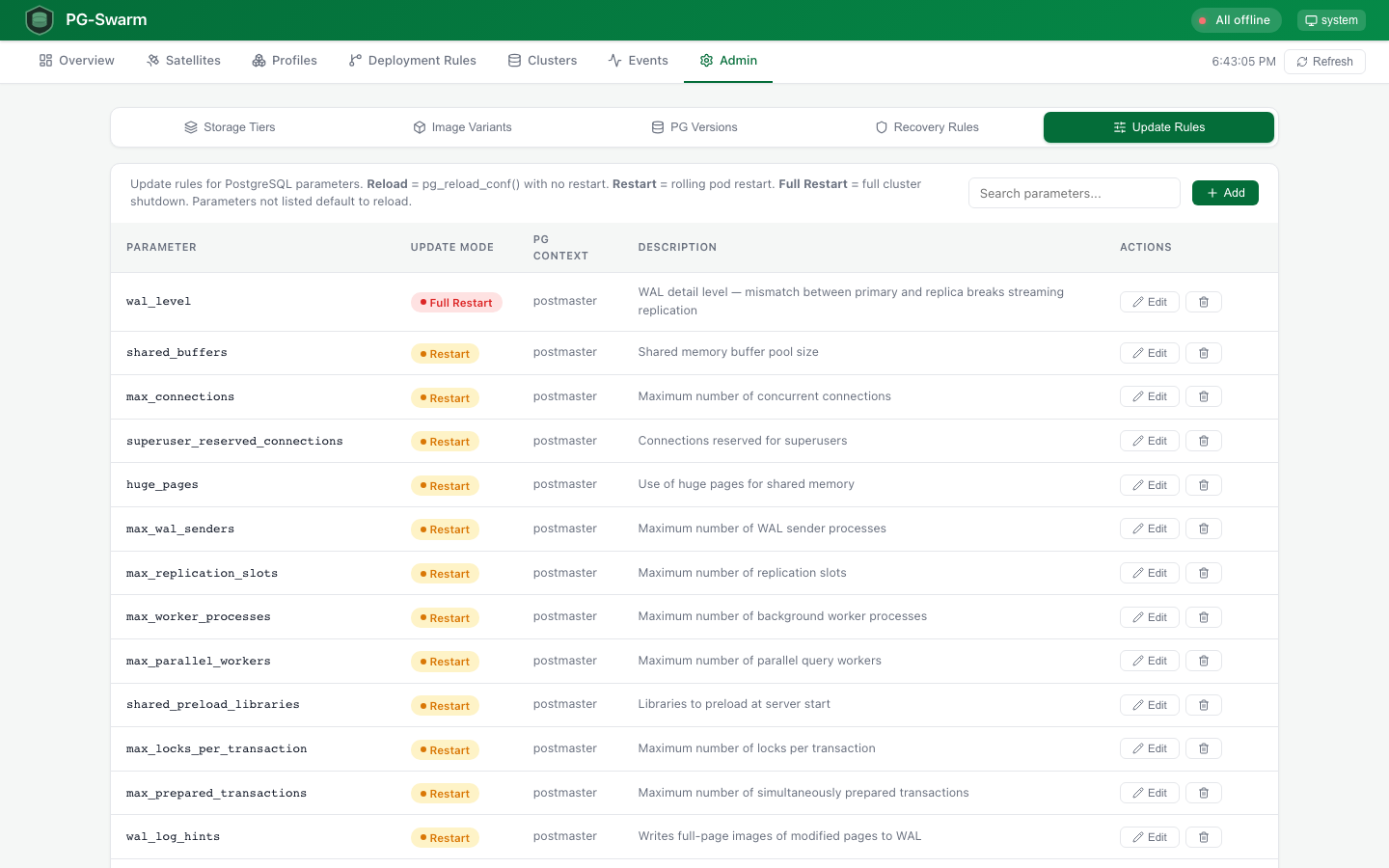
Update Rules
Admin panel for PostgreSQL parameter classification. Define which params use pg_reload_conf (sighup), rolling restart (postmaster), or full cluster shutdown (replication-sensitive).
Cluster Databases
Per-cluster database management tab. CREATE ROLE + CREATE DATABASE via sidecar command. CIDR-based IP access control (HBA rules) per database. Zero pod restart.
Config Versioning
Version history with revert for profile changes. Per-cluster approval workflow before config updates are applied. Full audit trail of every configuration change.
Event Log
State transitions, failovers, switchovers, backup completions, and errors with severity icons. Per-cluster event filtering.
Satellite Logs
Terminal-style log viewer with SSE streaming, server-side and client-side level filtering, remote log level control, auto-scroll, and clear.
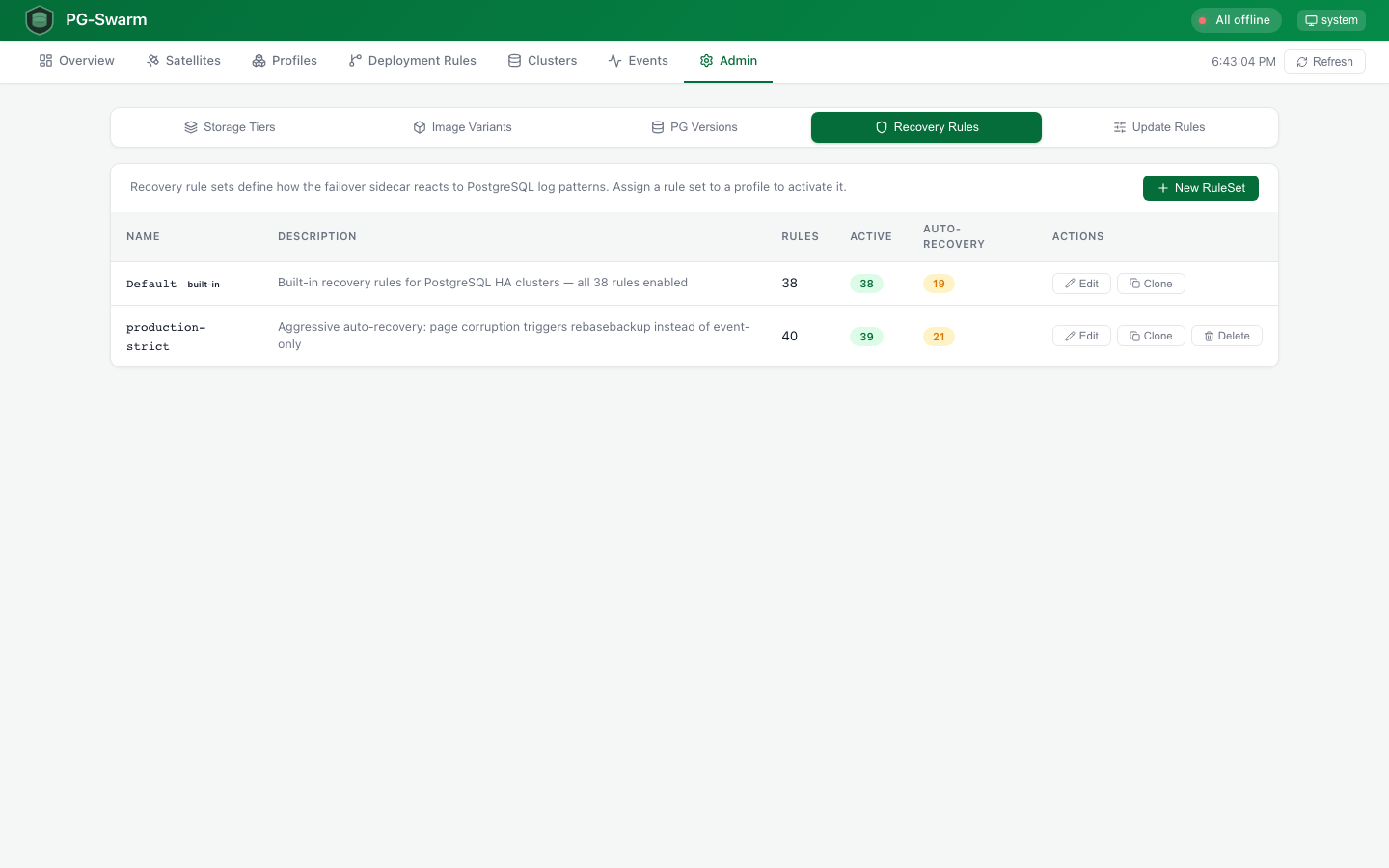
Recovery Rules
Centrally managed recovery rule sets with inline rule editing, pattern sandbox for testing regex against sample log lines, and per-cluster attachment.
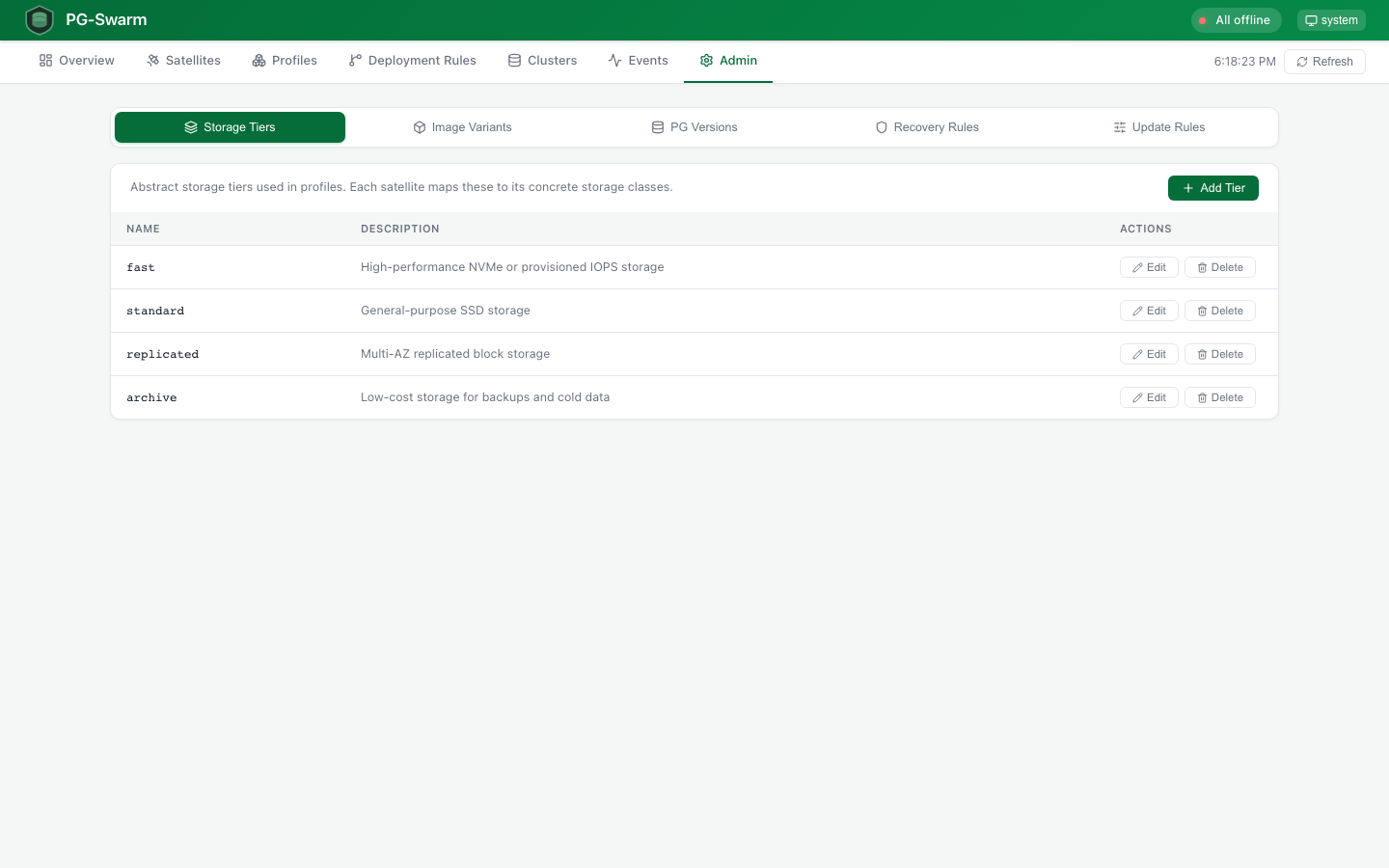
Admin Console
5-tab admin page: Storage Tiers with satellite mappings, Image Variants for postgres base images, PG Version registry, Recovery Rules editor, and Update Rules for parameter classification.
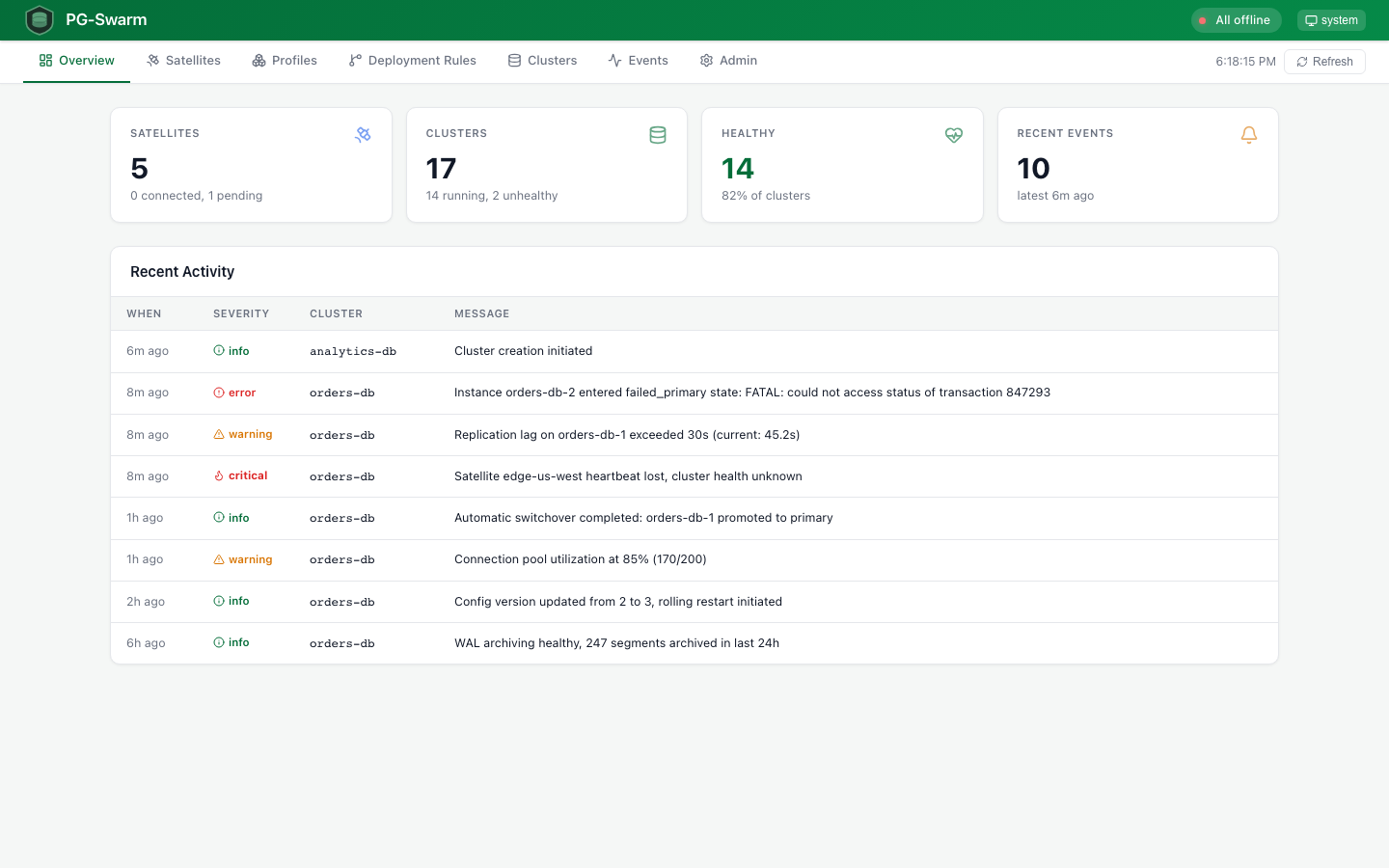 Overview
Overview
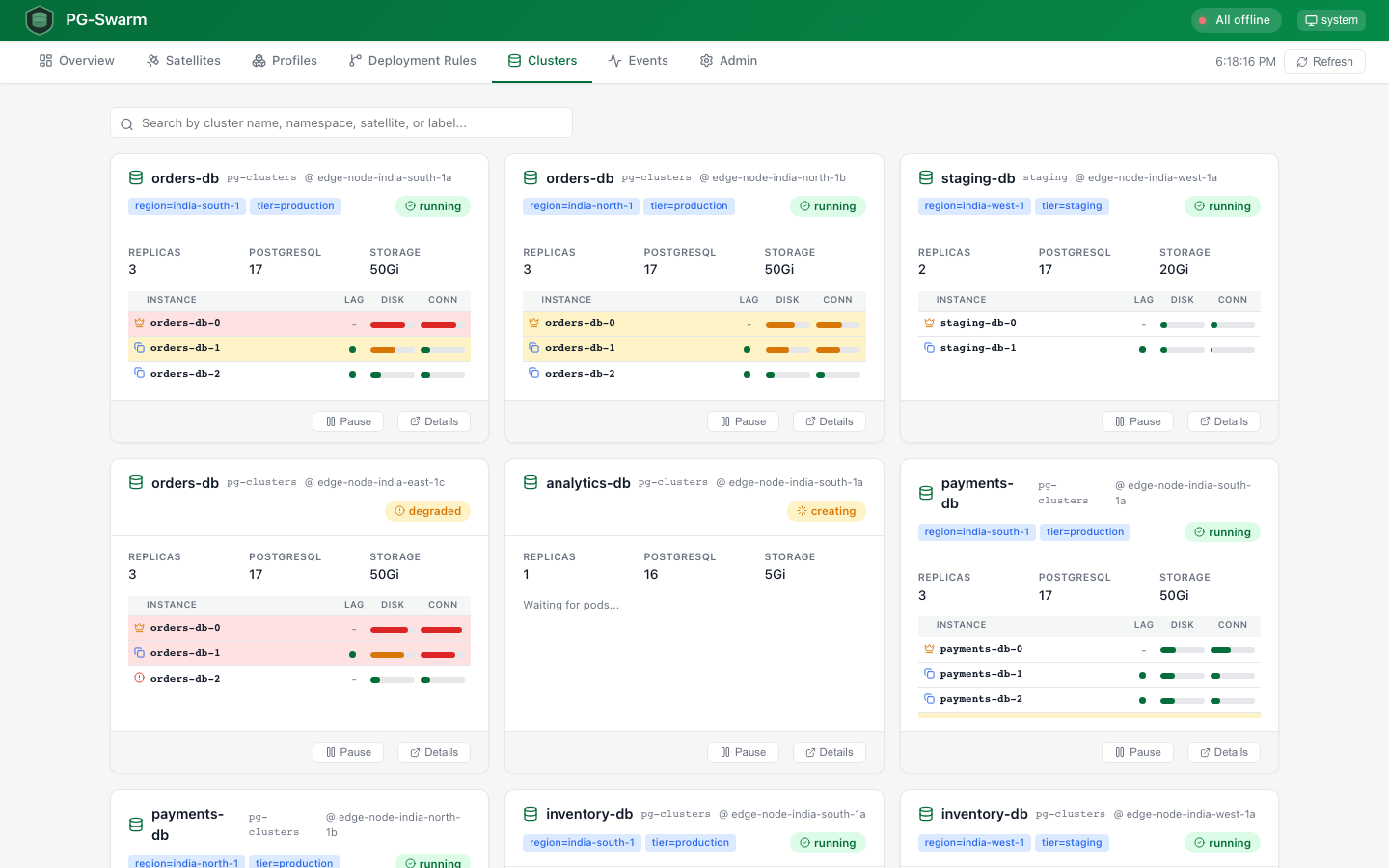 Clusters
Clusters
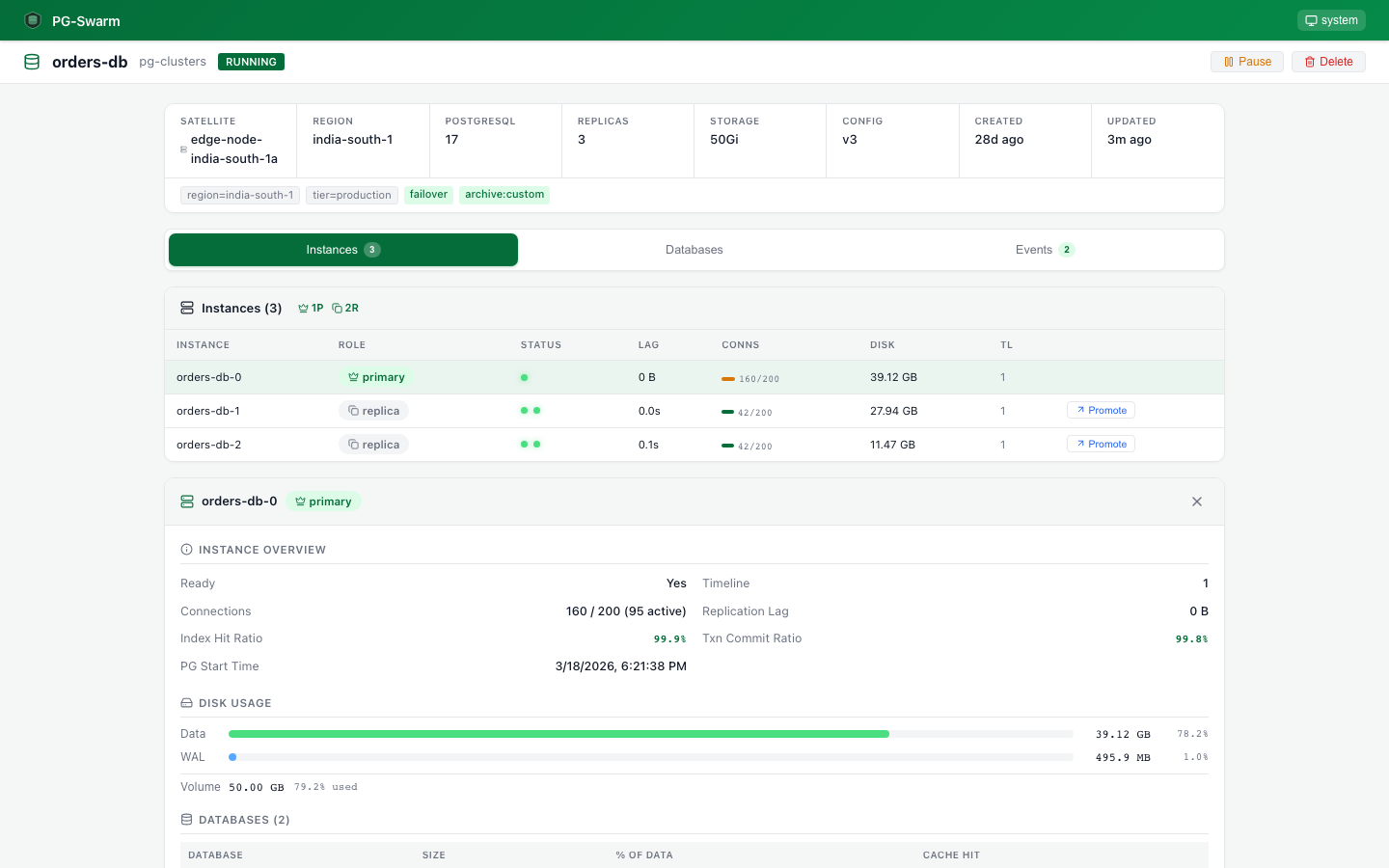 Cluster Detail
Cluster Detail
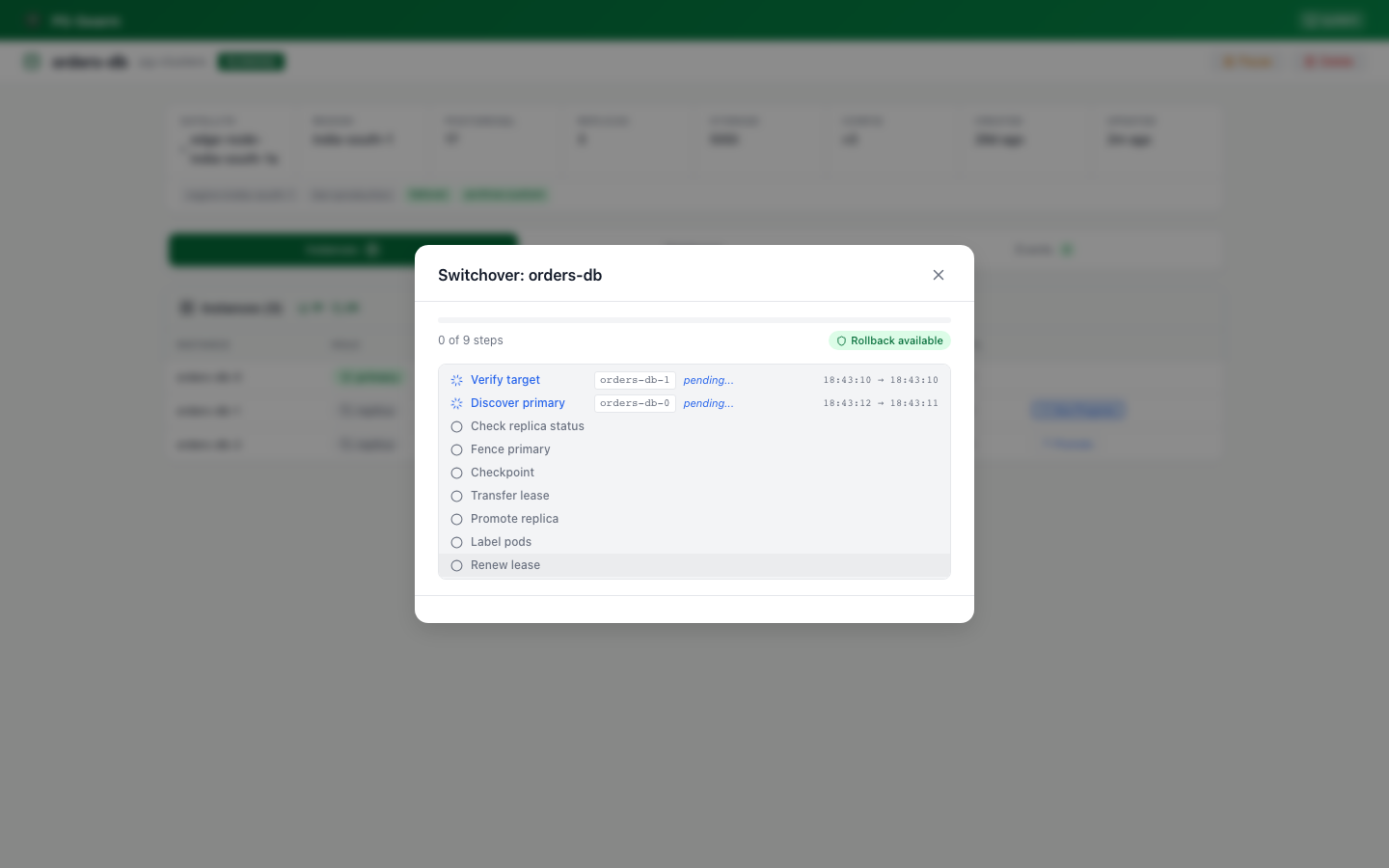 Switchover Progress
Switchover Progress
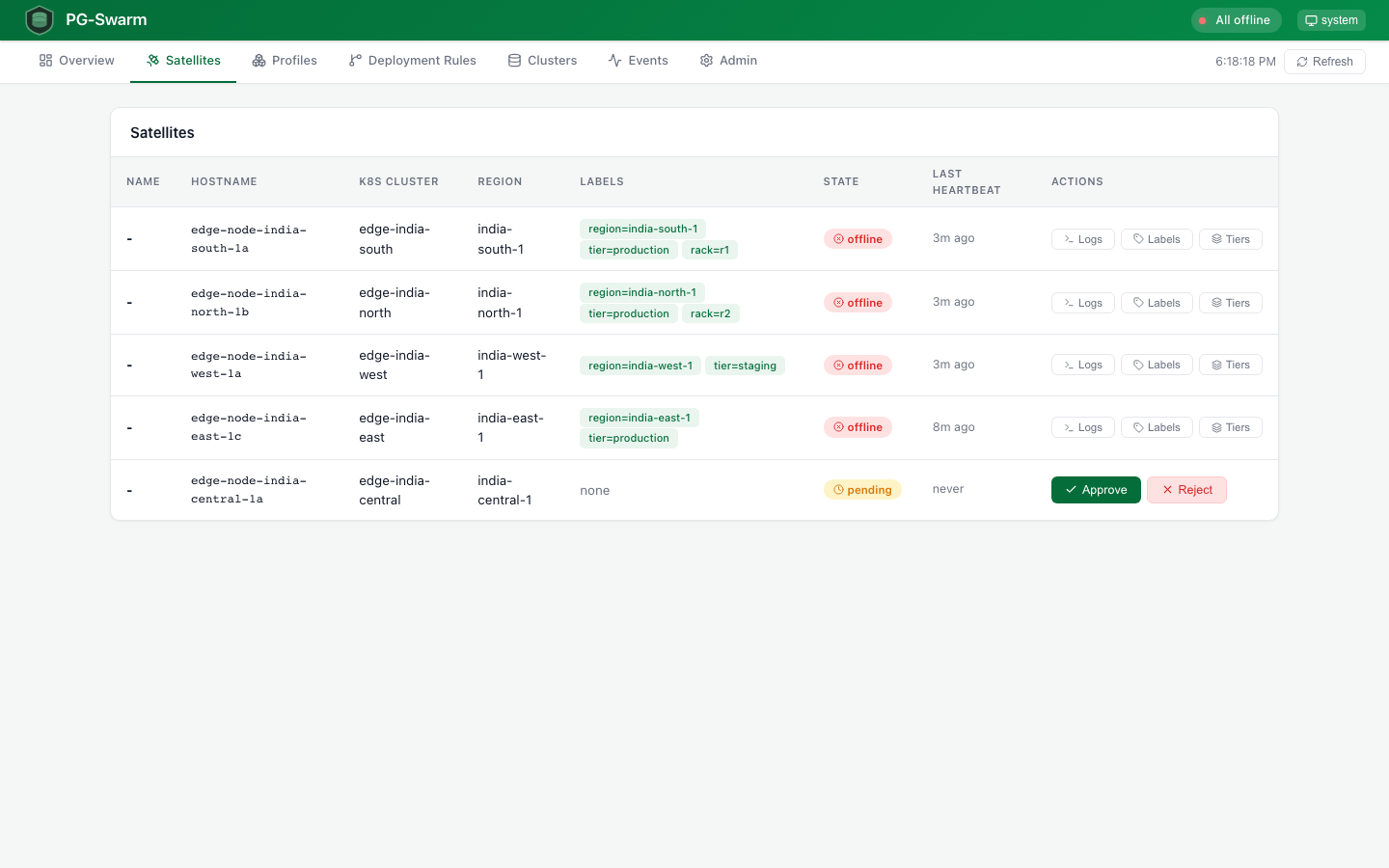 Satellites
Satellites
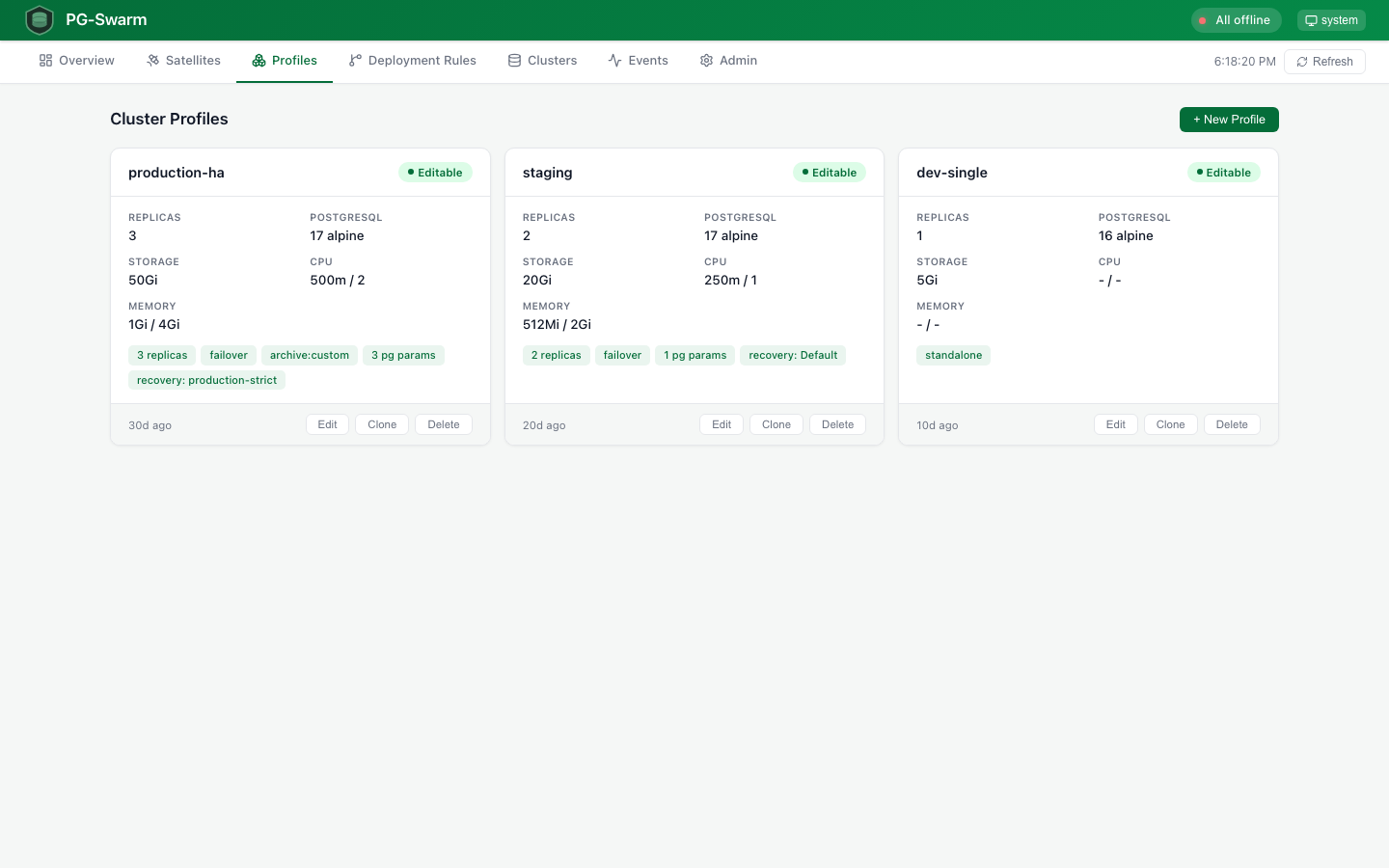 Profiles
Profiles
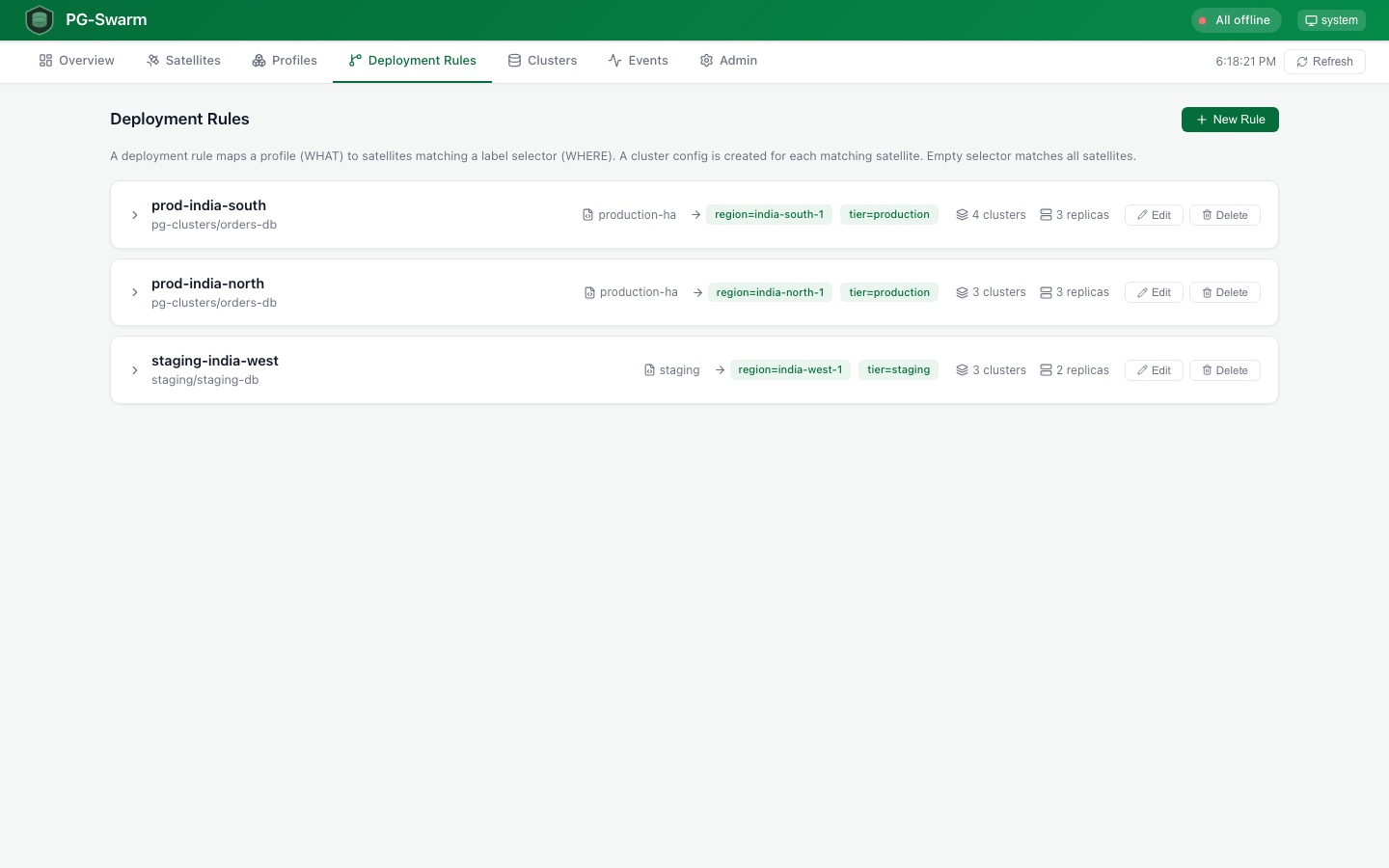 Deployment Rules
Deployment Rules
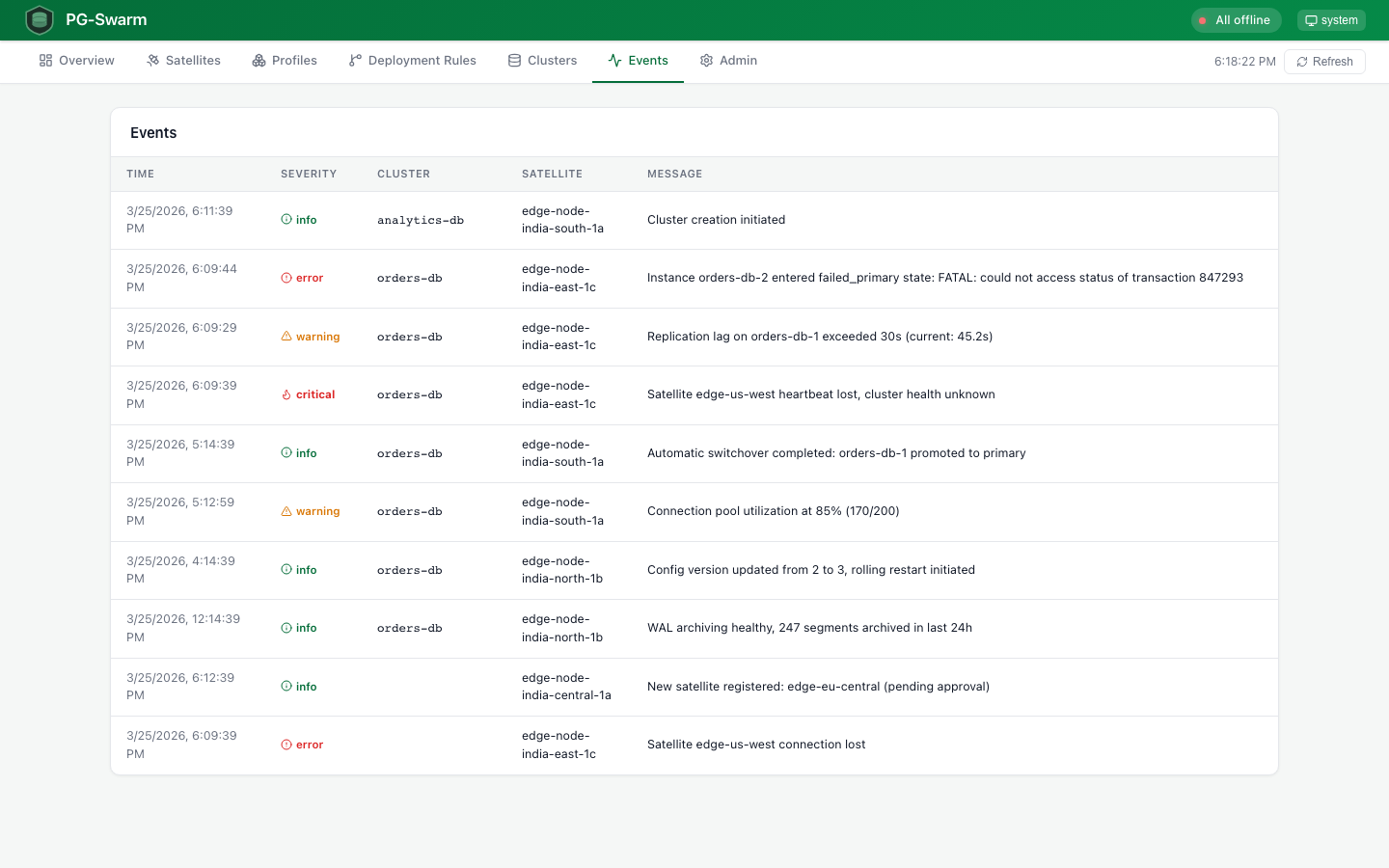 Events
Events
 Admin
Admin
 Recovery Rules
Recovery Rules
 Update Rules
Update Rules
